
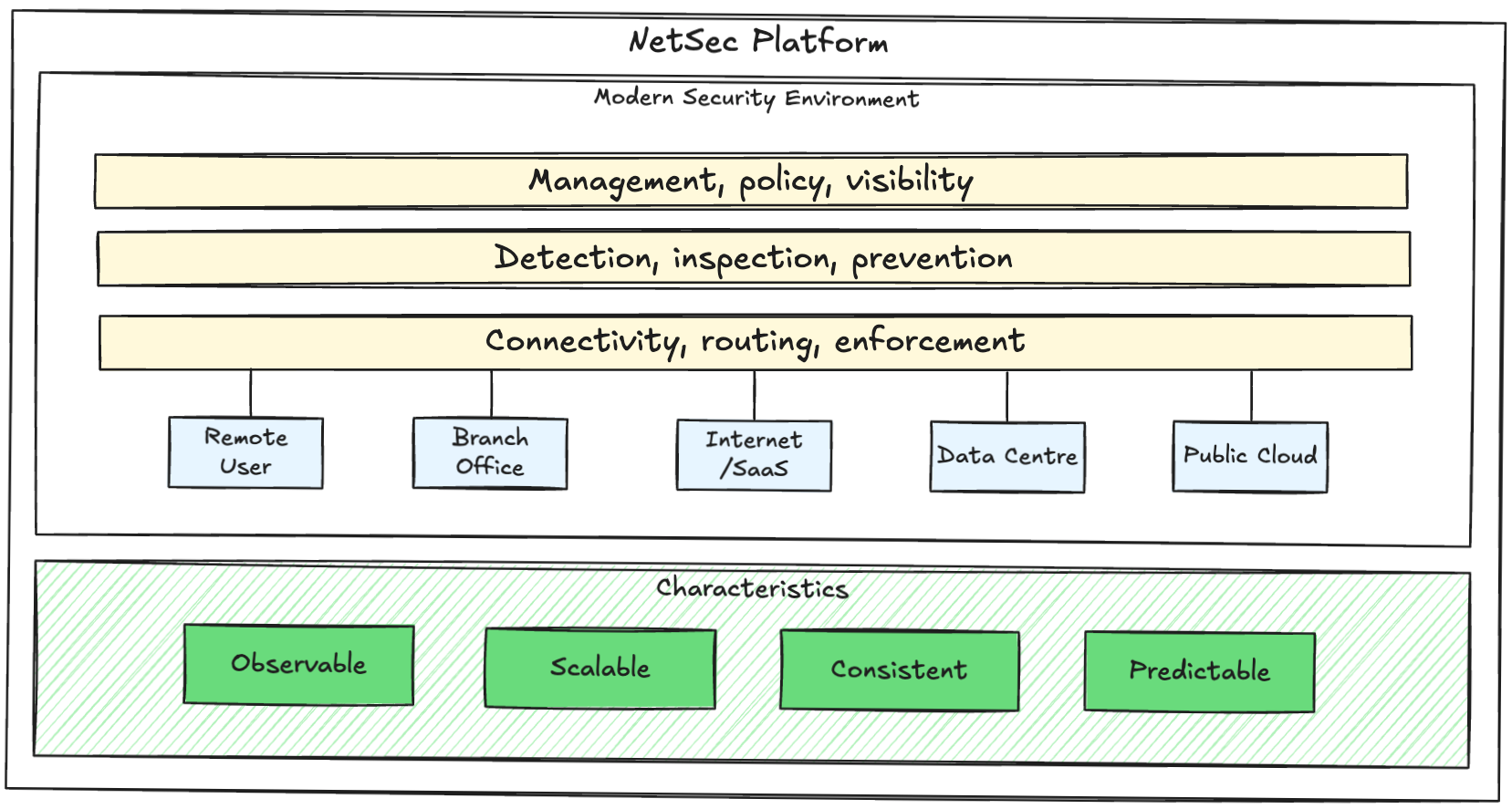
NetSec Platform: Building Blocks
A well implemented NetSec platform will give centralised intent and control, distributed enforcement, and shared visibility - consistently applied wherever your users and applications are active.
In this post I'll outline a simple reference model with example building blocks. It's intentionally pragmatic, the goal is to create a starting point you can scale without an unmanageable list of exceptions.
Building Blocks
A NetSec platform consists of core building blocks that can be grouped into 3 architectural layers:
- Connectivity, routing, enforcement
Connectivity and routing: connectivity isn't a network team detail, it is foundational to security outcomes. Your NetSec platform should define traffic steering to enforcement, private routing to applications, failover behaviour, and blast radius. If you don't intentionally design this you'll end up with inconsistent enforcement paths, poor user experience, and difficulty troubleshooting.
Design goal: predictability - in relation to path selection, failures, and user experience.
Distributed enforcement: this is about where the packet gets inspected, it will typically happen in 4 main places:
A) Remote users - the modern reality is that people are working from anywhere and often on unmanaged networks. Enforcement examples include Zero Trust Network Access (ZTNA) and agent-based Security Service Edge (SSE).
B) Branch and site edge - these locations need internet breakout controls, private connectivity, segmentation, and resilient access. They may also have considerations such as the increasing numbers of connected Operational Technology (OT) devices.
C) Cloud - workloads need north/south egress and ingress, east/west segmentation, and controlled connectivity to shared services and SaaS. Applications delivered as SaaS still require security inspection for use cases like Data Loss Prevention (DLP).
D) Data centre / legacy core - even cloud-first organisations usually have some legacy applications and shared services or partner connectivity. These environments are more likely to be using the old perimeter and trusted network approach.
Design goal: consistent policy enforcement across each location, despite technology and operational differences.
- Detection, inspection, prevention
Shared security services: inspection logic across distributed enforcement points must remain consistent to achieve scalability. Capabilities such as threat detection, malware analysis, DNS and URL controls, and behavioural analysis should be able to share inspection intelligence, detection models, and threat updates across the platform.
Design goal: intelligence and updates are applied centrally and consumed globally.
Identity and device context: identity is now the most important network security component. You need a consistent source of truth for users and groups, devices and posture, authentication and conditional access, and service accounts and non-human identities (such as AI agents).
Design goal: security policy should follow the user/device/app and not the IP address.
- Management, policy, visibility
Visibility and operations: a good platform provides end-to-end visibility with central logging and consistent event meaning, context enrichment, dashboards and analytics (that engineers actually use), and automated alert correlation and troubleshooting.
Design goal: troubleshooting steps and owners should be easy to identify and form a standard process.
Policy engine: policies should only grant the least amount of privilege required. This is known as Zero Trust - more on that in the next post. Your platform needs a policy model that supports a global baseline (minimum standards), application-specific policies, risk-based and dynamic policy decisions, and exceptions that are controlled, time-bound, and reviewable. That last one might sound counter intuitive, but it's important to plan for the worst.
Design goal: a policy framework should apply the principle of least privilege and keep its structure after 12 months of change.
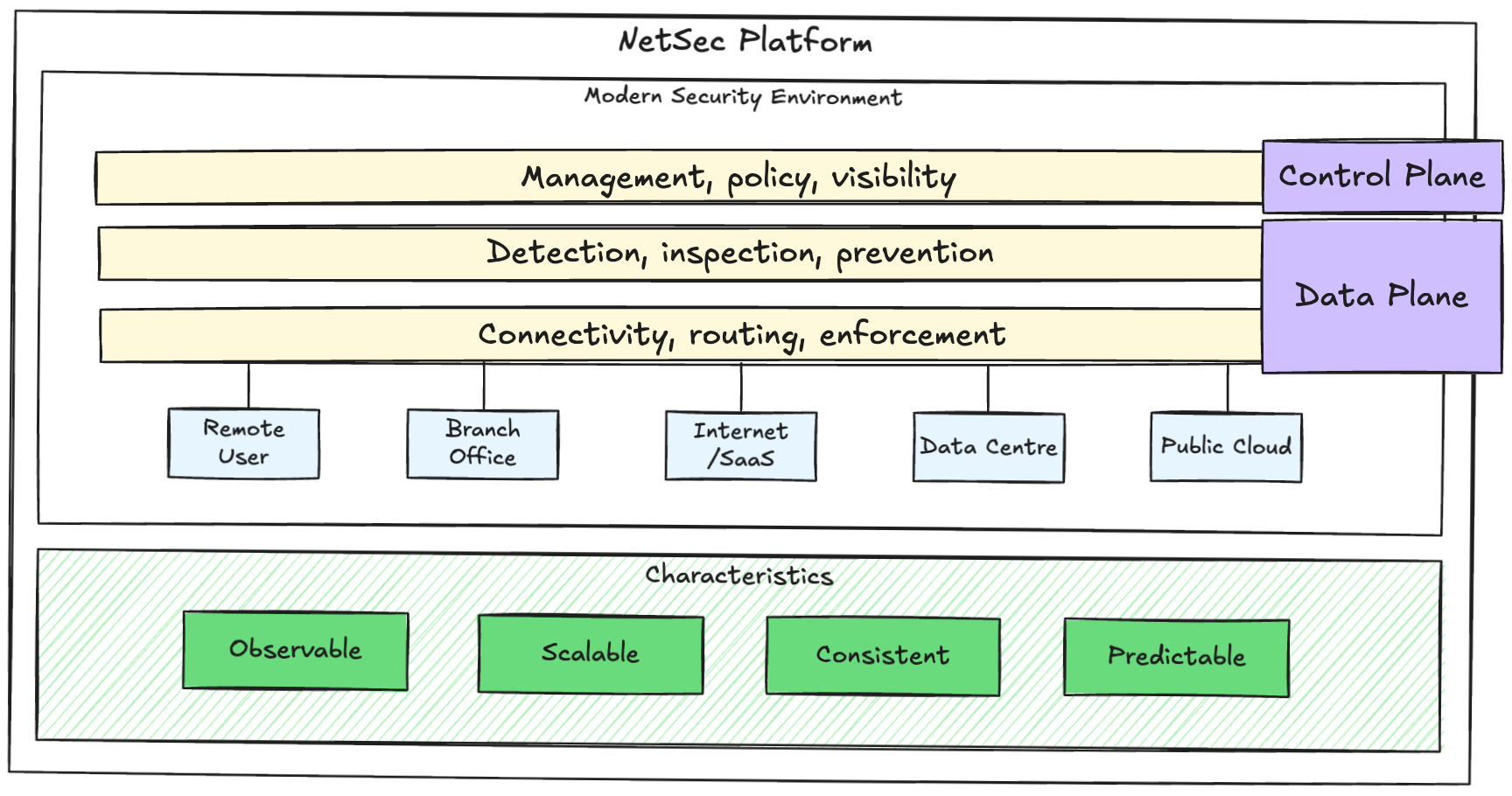
Control Plane vs Data Plane
It is important to understand the difference between the control plane and the data plane, since this split will drive design decisions.
The control plane is where you operate the platform and define security intent.
The data plane is where traffic is inspected and policy is enforced.
The typical responsibilities of a NetSec platform control plane include:
- Policy management
- Visibility and logging
- Configuration and lifecycle
- Identity and context
- Automation and integration
The data plane is where the work happens:
- Routing and connectivity
- Traffic inspection
- Decryption where required
- Segmentation and access enforcement
- Threat prevention
- URL filtering and DNS controls
The data plane should be designed for performance, resilience, and predictable enforcement. Your platform should not depend on a perfect network day to be secure.
Design Considerations
Not an exhaustive list, but some of the main things to consider:
Consideration 1: Where are your users and applications located and what are their access patterns?
This is probably the most important consideration. It will drive your coverage, segmentation boundaries, enforcement points, performance, and traffic steering design. What is your source of truth for identity? What is your authentication strategy and does it include session context? How will you discover and identify applications (including shadow IT)? How will you manage the lifecycle (onboarding and offboarding) of users, devices, and applications?
Consideration 2: What must continue working during outages?
Consider first your minimum viable X, for example if you're a hospital what does your minimum viable hospital look like? What do you need to keep the doors open? What are your critical assets and dependencies? This will feed in to your platform design - what happens if a region or service edge fails? What does 'degraded mode' look like? What happens if the control plane is unreachable? You don't want security to disappear during instability, but you also don't want your minimum viable business to stop.
Consideration 3: Define operational ownership.
Make sure you're clear who is responsible for things like policy, routing, identity, and endpoints. Key stakeholders will help you define your policy model, change and exception process, governance, and troubleshooting workflows. This shapes metrics that matter like user-impacting incidents and Mean Time To Resolve (MTTR).
Consideration 4: Prioritise visibility.
Visibility must be a platform feature from the start, not an add-on. If logs are scattered then incidents take longer to resolve, change becomes riskier, and teams lose confidence. Ensure visibility early including log collection and retention strategy, consistent data model and event meaning, and ecosystem integrations such as XDR and SIEM.
Consideration 5: Automation should be possible even if you don't start there.
You probably won't automate everything on day 1, but you should avoid decisions that make it difficult later. That means standardised processes, names, and configurations, consistent templates, API-friendly workflows, and minimising manual one-offs.
Operational Outcomes
If you've implemented this model successfully you'll notice:
- New sites are onboarded using standard patterns
- Remote access behaves consistently for users
- Policy remains understandable and reviewable as the environment scales
- Troubleshooting is repeatable and fast
- Leadership can see risk and control coverage clearly
What's Next?
Now that we've established the platform building blocks, we can map real technologies.