
NetSec Platform: Building Blocks
In the previous post, I described a some of the challenges with traditional network security. If you are new to the discussion, it is worth reviewing that post before continuing.
This article will outline a simple reference model for a NetSec platform with centralised intent, control, and visibility, and distributed enforcement - consistently applied wherever users and applications are active.
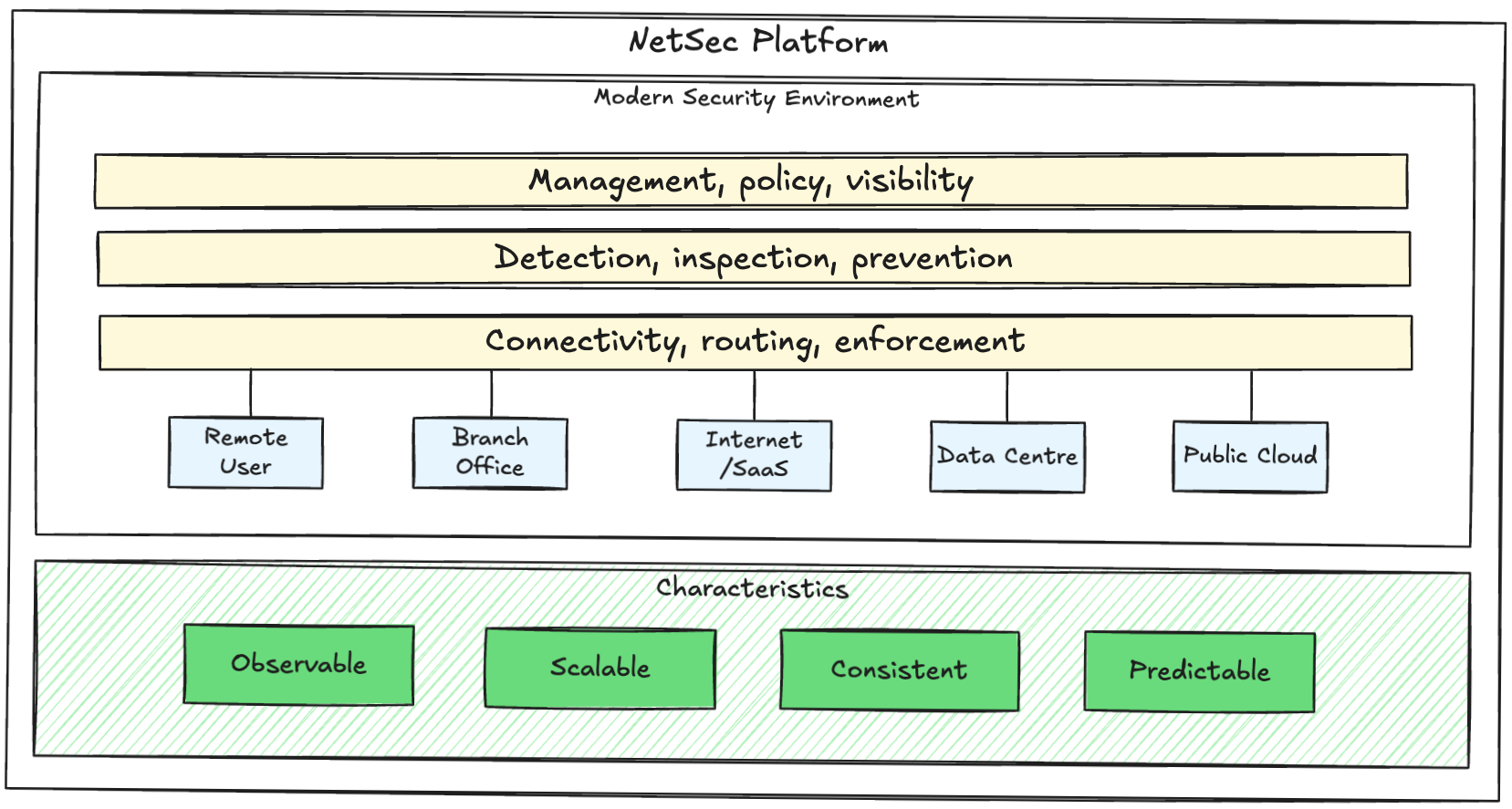
The core building blocks can be grouped into 3 architectural layers:
Layer 1: connectivity, routing, enforcement: defines traffic steering, enforcement points, private routing to applications, failover behaviour, and blast radius. Covers all applicable access patterns such as remote users, branch and site edge, data centre, and cloud. Without this intentional design user experience will be poor and troubleshooting difficult.
Design goal: predictable user experience and policy enforcement.
Layer 2: detection, inspection, prevention: shared inspection logic and intelligence with security capabilities such as threat and malware prevention, DNS and DLP controls, URL filtering, decryption, and behavioural analysis. Security controls should be applied inline and in parallel.
Design goal: security controls defined centrally and consumed globally.
Layer 3: management, policy, visibility: end-to-end visibility including digital experience management, automated alert correlation, context enrichment, central logging, and consistent event meaning. Policies should be aligned with a consistent source of truth for identity, factor in dynamic risk and context variables, and only grant the least amount of privilege required.
Design goal: policy framework scales with minimal exceptions.
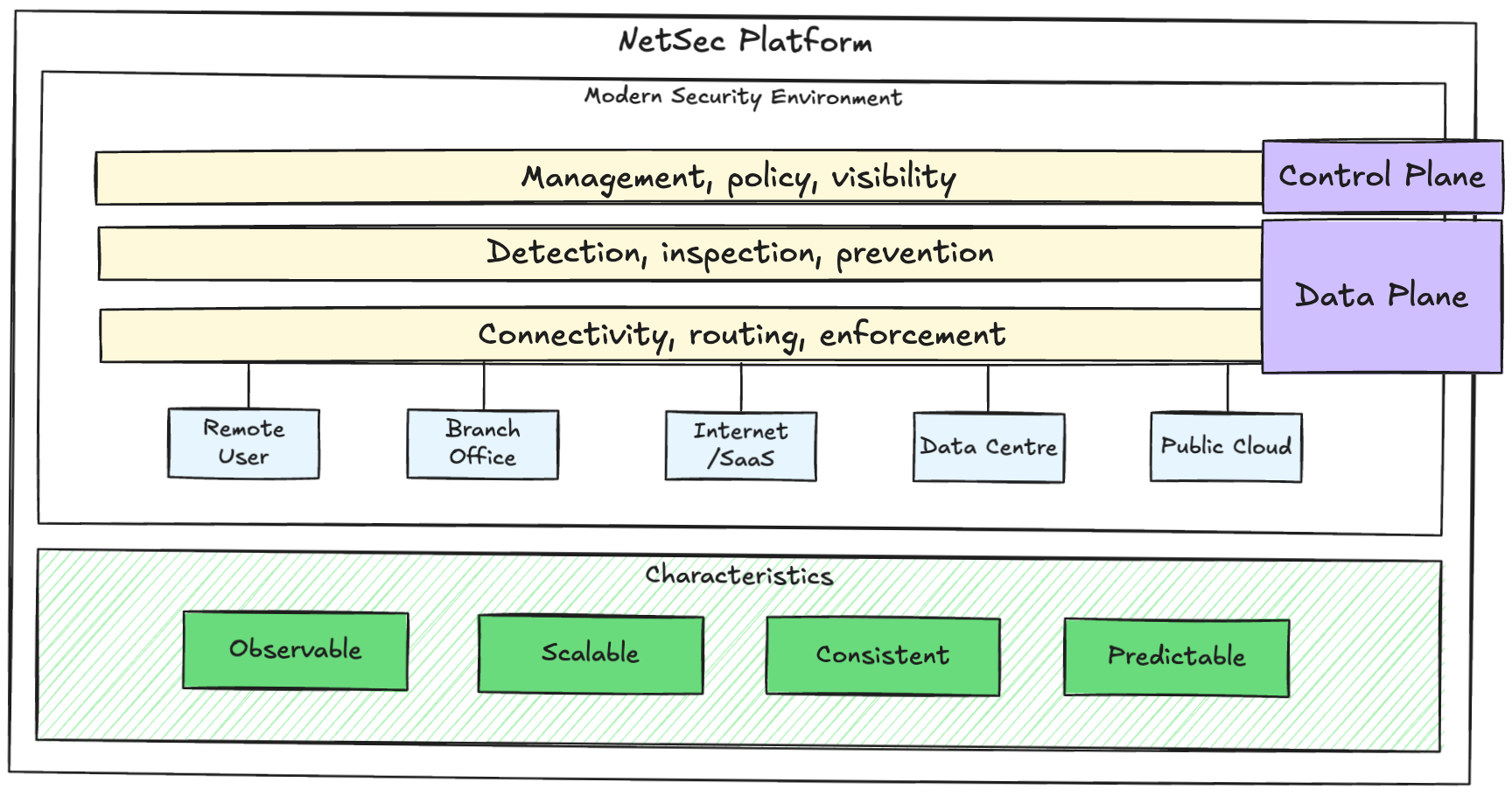
Control Plane vs Data Plane
It is important to understand the difference between the control plane and the data plane, since both will drive design decisions.
The control plane is where the platform is operated and security intent is defined.
The data plane is where traffic is inspected and policy is enforced.
The typical responsibilities of a NetSec platform control plane include:
- Policy management
- Visibility and logging
- Configuration and lifecycle management
- Identity and context
- Automation and integration
The data plane is where the work happens:
- Routing and connectivity
- Traffic inspection
- Decryption where required
- Segmentation and policy enforcement
Design Considerations
Not an exhaustive list, but some of the main things to consider:
Consideration 1: where are users and applications located and what are their access patterns?
This is probably the most important consideration. It will drive coverage, segmentation boundaries, enforcement points, performance, and traffic steering design. What is the source of truth for identity? What is the authentication strategy and does it include session context? How are applications, including shadow IT, discovered and identified? How are user, device, and application lifecycles managed?
Consideration 2: what must continue working during outages?
Consider the minimum viable business or organisation equivalent. What is needed to keep the doors open? What are the critical assets and dependencies? This will feed into the platform design - what happens if a region or service edge fails? What does 'degraded mode' look like? What happens if the control plane is unreachable? Security shouldn't disappear during instability, but critical services cannot stop either.
Consideration 3: define operational ownership.
Make sure roles and responsibilities are clearly defined for areas including policy, routing, identity, and endpoints. Key stakeholders will help define the policy model, change and exception process, governance, and troubleshooting workflows. This shapes metrics like user-impacting incidents and Mean Time To Resolve (MTTR).
Consideration 4: prioritise visibility.
Visibility must be a platform feature from the start, not an add-on. If logs are scattered then incidents take longer to resolve, change becomes riskier, and teams lose confidence. Ensure visibility early including log collection and retention strategy, a consistent data model and event meaning, and ecosystem integrations.
Consideration 5: automation should be possible even if isn't implemented on day 1.
Avoid making decisions that make automation difficult later. Standardise processes, names, and configurations. Use consistent templates and API-friendly workflows, and minimise manual one-offs.
Operational Outcomes
A successfully implemented platform model delivers the following outcomes:
- New sites are onboarded using standard patterns
- Remote access behaves consistently for users
- Policy remains understandable and reviewable as the environment scales
- Troubleshooting is repeatable and fast
- Leadership can see risk and control coverage clearly
What's Next?
Now that we've established the platform building blocks, we can map real technologies.